Transformer and Pipeline Brief Description#

Image by Robson Machado
What is Transformer?#
The Transformer is a protocol that defines the input port and output port.
It is just like a pipe in the real world.

Direction:
fit,transformandfit_transformgo forward.inverse_transformgoes backward.
Minimal methods require:
transformandfit_transformare necessary methods.fitandinverse_transformare optional method.
What is Pipeline?#
The Pipeline combines each port of Transformer into a stream.
You could control the direction of the stream to go forward or backward. And you could stop the stream where you want and check its internal.
It is just like a real pipeline in the real world.
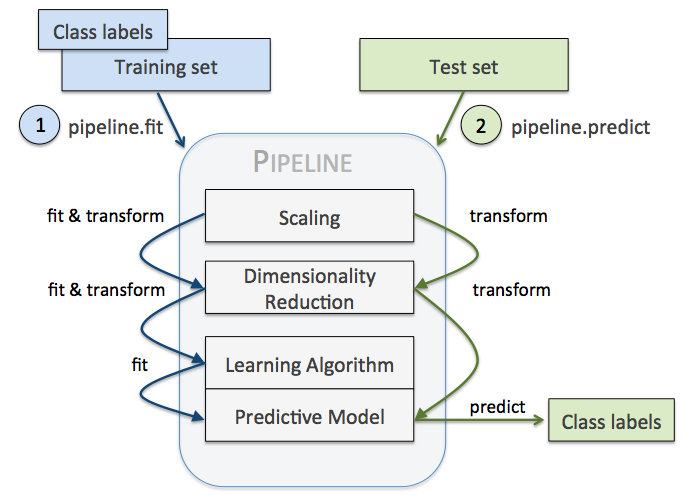
What transformer does?#
dtoolkit.transformer does two things:
Let
DataFrameas the basic data structure ofTransformer.Transform all methods / algorithms into
Transformer.
DataFrame in and DataFrame out#
sklearn.base.TransformerMixin let array-like in array-like out.
As if there has a pipeline [DropColumnTF, DropRowTF, Map, MapColumnTF].
If we put a DataFrame into this pipeline and want to debug and check the preprocessing data. However, it is hard to trace the data changing. There is only left data itself, other information is missing.
It is important to keep trace the data changing. So dtoolkit.transformer would keep the DataFrame unchanged in stream, let DataFrame in and DataFrame out.

Engineering of Data Preprocessing#
dtoolkit.transformer could handle what a mess codes of data preprocessing codes.
A surprise comes here. It can face to the engineering of data preprocessing.
DataFramegives a good view to show the data.Transformercontains the processing or transforming methods.Pipelineas the manager to control the running.

What’s Next - Future Features#
There are two articles about some future features of Transformer and Pipeline.